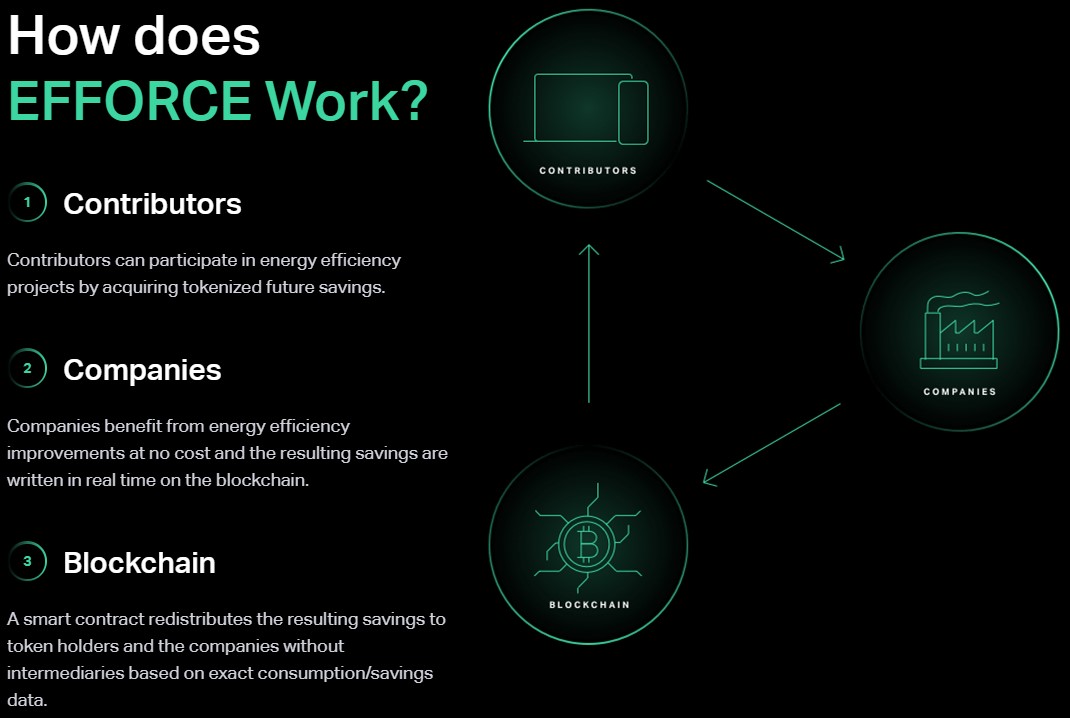


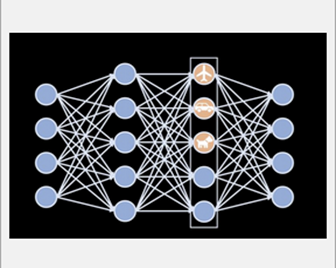
What exactly goes on in the minds of machines that learn to see? Duke University’s computer science professor, Cynthia Rudin, set out to define exactly what happens in between input and output in deep learning models. The complexity involved makes it difficult to know what information they are leveraging to “learn”, possibly yielding learning that is flawed.
Traditionally, the approach is to attempt to figure out why a computer vision system gets to the right answer after the fact, instead of taking in the reasoning necessary to arrive at a conclusion. The Duke team is using a method that trains the network to show its work by expressing how much it calls to mind different concepts to help decipher what it sees within the layers of the network. The results are the possibility of identifying objects and scenes in images just as accurately as the original network while gaining substantial interpretability in the network’s reasoning process.
The method controls the way information flows through it. By replacing one standard part of a neural network, only one neuron controls the information for one concept at a time, making it easier to understand how the network “thinks” and capture important aspects of the network’s train of thought.
Used to detect skin cancer from photos and tumors from chest x-rays, the team’s work has so far yielded a network that can form concepts on its own rather than from training labels and has revealed a dataset shortcoming.
Rudin claims that their solution is simple to use and eliminates putting blind faith in black-box models without knowing what goes on behind the scenes.