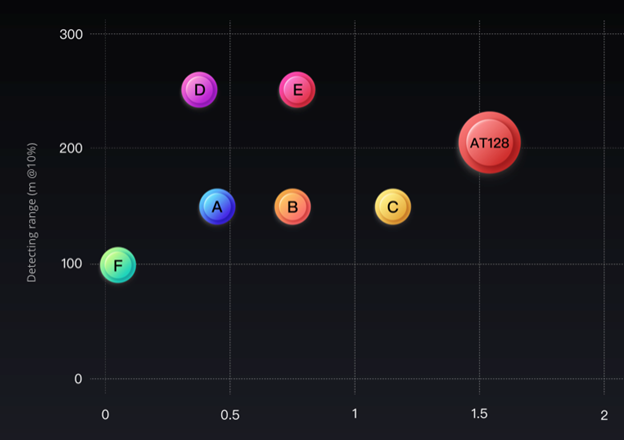


A team of researchers from UC San Diego recently unveiled their ability to make AI-generated voices more expressive, with minimum training. Their text-to-speech method is also applicable to voices not part of the system’s training set.
Targeting personal assistants for smartphones, homes, and cars, the training method can also be used in voice-overs for animated movies and automatic speech translation in multiple languages. It could also help create personalized speech interfaces that empower individuals who have lost the ability to speak.
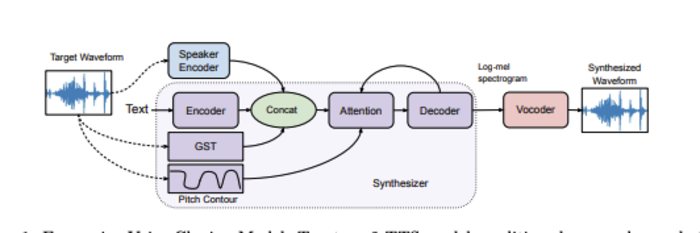
The method developed by the UC San Diego team is the only one that can generate expressive speech for a subject that has not been part of its training set with minimal training. By flagging the pitch and rhythm of the speech in training samples, their cloning system can generate expressive speech even for voices never encountered before. It can also learn speech directly from text; reconstruct a speech sample from a target speaker; and transfer the pitch and rhythm of speech from a different expressive speaker into cloned speech for the target speaker. Audio examples demonstrated here: https://expressivecloning.github.io/