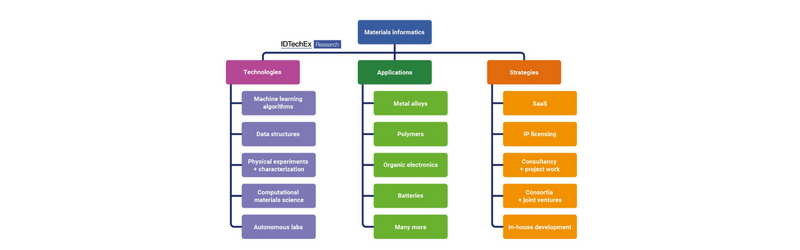



Do you want to play a game?
Creating artificial intelligence agents that compete and cooperate as effectively as humans remains a challenge—the issue is enabling AI agents to anticipate the future behaviors of other agents when they are all learning simultaneously. So far, these agents can only guess the next few moves of their teammates or competitors.
MIT-IBM Watson AI Lab researchers developed a new approach, giving agents a farsighted perspective. The machine-learning framework enables cooperative or competitive AI agents to consider what other agents will do as time approaches infinity vs. the few next steps. Behavior is then adapted to influence other agents’ future behaviors, arriving at an optimal, long-term solution.
To do this, researchers focused on multiagent reinforcement learning. Reinforcement learning is where an AI agent learns by trial and error. Researchers reward the agent for “good” behaviors, and the agent adapts its behavior to maximize that reward until it eventually becomes an expert. However, with several agents, the problem requires too much computational power to solve efficiently.
It’s impossible to plug infinity into an algorithm. So, the researchers designed their system so agents focus on a future point where their behavior will converge with that of other agents, or equilibrium. An effective agent actively influences the future behaviors of other agents, so they reach a desirable equilibrium from the agent’s perspective, converging to “active equilibrium.”
The machine-learning framework they developed, known as FURTHER (FUlly Reinforcing acTive influence witH averagE Reward), enables agents to adapt their behaviors as they interact with other agents to achieve this active equilibrium.
FURTHER does this using two machine-learning modules. The first, an inference module, enables an agent to guess the future behaviors of other agents and the learning algorithms they use based solely on their prior actions. Researchers tested the approach against other multiagent reinforcement learning frameworks in several different game scenarios, and the AI agents using FURTHER won games more often.